What is Deep Learning?
Deep learning is a sub-domain of machine learning focused on creating deep neural networks. The image below is a Venn Diagram showing the overlap between AI, ML, and deep learning that I suppose I more or less agree with.
Like other ML models/subdisciplines, deep learning focuses on models flexibly learning from data. Sure, the modeler specifies the model architecture, and different architectures are more suited for different tasks, but there are fewer assumptions “built into” neural networks than there are in, say, linear regressions. This makes them flexible enough to learn from data, but it also makes them prone to under- or over-fitting if there isn’t enough data to learn from.
Even though deep learning models are, I think, technically parametric models (in that they have a fixed number of parameters once the model is specified), I tend to think of them as more akin to (nonparametric) random forest or boosted tree models, maybe because they’re big? But that’s not actually correct, I suppose.
What we mean by “deep” neural networks is that the input data passes through multiple layers in a network. In each layer, the input is progressively refined (via matrix multiplication and some activation function) before being passed to the next layer. This concept is both very flexible and very powerful. Deep neural networks have proven to be useful in computer vision, natural language processing, auditory processing, and more.
I’ll have examples and other more specific use cases related to deep learning throughout this section of the website.
A Basic Fully-Connected Neural Net
Here’s a diagram of a fully-connected neural network. Each layer is “densely” connected to the subsequent layer (i.e. all nodes in layer i are connected to all nodes in layer i+1). In this model, nodes are inputs/outputs, and the lines represent some function that transforms a node into the subsequent node (usually matrix multiplication plus some activation function).
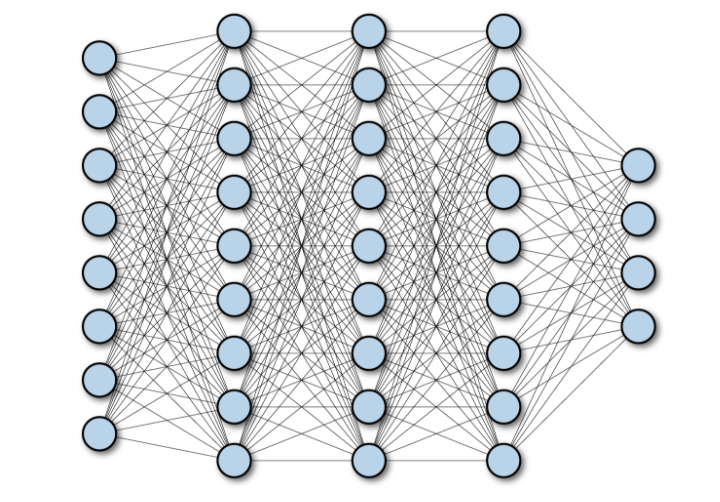
The number of nodes in each layer is flexible and is up to the modeler to determine, as is the total number of layers. According to Jeremy Howard’s fastai book (see the “Going Deeper” section), it’s typically more computationally efficient to use more smaller layers than fewer large layers, and this approach can also get us better performance. The last layer should have j nodes, where j is the number of outputs. In a regression problem, this will be 1. In a classification problem, it can be the number of classes, k, of the outcome variable. Or it can be, equivalently, k-1, assuming membership in only 1 class.
Deep Learning Frameworks
Most deep learning projects are going to happen in Python. I’m going to preface this by saying I’m not a deep learning expert, but my understanding is that PyTorch is probably the most popular deep learning framework in 2024. It’s the only framework I’ve used in Python, but it feels pretty straightforward to work with. Plus there are tons of examples online.
fastai is a higher-level framework that simplifies/abstracts away some of the lower-level stuff in PyTorch. It makes it very easy to quickly train (or fine-tune) models to solve a variety of problems. I like it a lot, and it feels almost like cheating to use it…
I’ve never used Tensorflow, but I think it’s also still fairly popular (although less so than PyTorch?).
In terms of non-Python frameworks, I like Julia’s Flux framework. It feels easy to use and, since it’s written in pure Julia, it’s easy to extend and it integrates well with other Julia code. I haven’t used it extensively, but I’ve enjoyed my limited experience with it. It’s kind of a hipster framework, so there are fewer worked examples online.
I’ve also dabbled in R’s torch ecosystem. I tend to use R more than Python or Julia in my day-to-day work, but R-torch is probably my least-favorite of the deep learning frameworks I’ve used. The API feels like it’s trying to mimic Python syntax, which feels awkward in R (if I wanted Python, I’d just use Python). Again, I don’t have extensive experience with torch, so maybe I’m missing something.